Zusammenfassung der Studie Big Data im Freistaat Bayern – Chancen und Herausforderungen
Die digitale Revolution verändert das Wirtschaftsgeschehen und die Gesellschaft in hohem Tempo. Infolge dieser radikalen Veränderungen vermehren sich explosionsartig die damit verbundenen Datenmengen. Im Jahr 2013 wurden so viele Daten produziert, wie in der gesamten Menschheitsgeschichte zuvor. Heute liegt der Bestand bei rund 12 Zettabyte, und die Menge wächst täglich rasant an – für 2020 rechnet man mit etwa 40 Zettabyte. Von diesen Daten sind allerdings rund 90 Prozent unstrukturiert, nur etwa drei Prozent lassen sich zum Beispiel über ein Schlagwort suchen. Klassische Datenbankarchitekturen und Auswertungsmöglichkeiten geraten hier an ihre Grenzen.
In der vbw Studie Big Data im Freistaat Bayern – Chancen und Herausforderungen (Prognos / Heckmann, 2016) werden der Status quo von Forschung und praktischer Anwendung in Bayern, Potenziale und Herausforderungen sowie die rechtlichen Rahmenbedingungen analysiert. Auf den Ergebnissen bauen die Handlungsempfehlungen des Zukunftsrats der Bayerischen Wirtschaft auf. Die Kernergebnisse der Studie sind im Folgenden zusammengefasst.
Big-Data-Technologien und -Anwendungen ermöglichen die Analyse von Daten, die zu groß oder zu komplex sind oder sich in zu großer Geschwindigkeit ändern, um sie mit den klassischen Methoden der Datenverarbeitung auswerten zu können. Den Kern von Big Data bildet aber nicht nur das Handling großer Datenvolumina. Erstmalig können große Mengen unstrukturierter, heterogener, unvollständiger und sogar fehlerhafter Daten verarbeitet werden – mit dem Ziel, valide Ergebnisse hervorzubringen.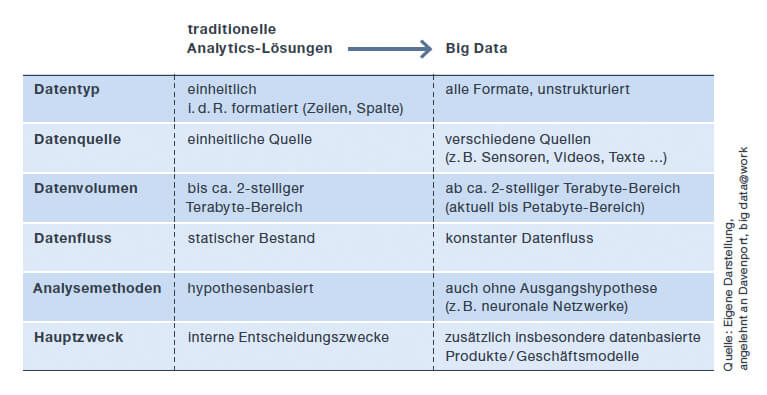
Daten sind
- im computerspezifischen / informatischen Sinn jede Form von alphanumerischen Zeichen,
- nach DIN 44300 Teil 2 Nr. 2.1.13 Gebilde aus Zeichen, die aufgrund bekannter oder unterstellter Abmachungen Informationen darstellen, vorrangig zum Zwecke der Verarbeitung oder als deren Ergebnis,
- im strafrechtlichen Sinn je nach Vorschrift unterschiedlich definiert: § 202 a Abs. 2 StGB geht beispielsweise von einem Datenbegriff aus, der nur solche Daten erfasst, die elektronisch, magnetisch oder sonst nicht unmittelbar und wahrnehmbar gespeichert sind,
- im Sinne des Datenschutzrechts sämtliche Informationen über persönliche und sachliche Verhältnisse einer natürlichen Person, unabhängig von der Form der Darstellung oder Speicherung.
Für Big Data sind sämtliche Erscheinungsformen relevant. Hier spielen sowohl „Rohdaten“ als auch „aggregierte Daten“ eine Rolle. Rohdaten sind alle Daten in ihrer ursprünglich erfassten Form, aggregierte Daten sind Daten, die je nach Systemanforderung zusammengefasst, kategorisiert oder interpretiert worden sind. Big Data umfasst zugleich einen grundlegenden Wandel der Nutzung des verfügbaren Wissens – nahezu in Echtzeit und weltweit –, der dazu führt, dass neue Wettbewerber neue Dienstleistungen und Produkte in etablierten Märkten platzieren können. Produkte werden zukünftig sehr viel stärker mit Sensoren und Funkschnittstellen ausgestattet. Big Data zieht dadurch auch in traditionelleren Produktionsbereichen ein. Big-Data-Technologien und -Anwendungen profitieren bei ihrer Entwicklung und Ausbreitung von denselben günstigen Rahmenbedingungen wie die Digitalisierung im Ganzen, insbesondere von der steigenden Rechenleistung und dem Hardwarepreisverfall. Speziell für Big Data wirken sich die Verfügbarkeit von Open-Source-Produkten und die stetig steigende Datenmenge, unter anderem durch die Ausbreitung des „Internets der Dinge“, in dem internetfähige Objekte (z. B. Maschinen, Sensoren etc.) miteinander kommunizieren, beschleunigend aus.
Der Rechtsrahmen für Big Data
Rechtliche Unsicherheiten, vor allem im Hinblick auf den Datenschutz, werden regelmäßig als zentrales Hemmnis genannt. Insoweit nimmt das Recht eine Schlüsselrolle ein. Hier ist die Herausforderung bei Big Data, den Paradigmenwechsel in der Datenverarbeitung zu erklären und den diffusen Ängsten mit Transparenz und Sachlichkeit zu begegnen.
Das Recht und die Rechtssicherheit spielen eine zentrale Rolle beim Thema Big Data. Zum einen werden bei den Hemmnissen für die Einführung neuer IKT-Lösungen vor allem in kleinen und mittelständischen Unternehmen immer wieder die Themen Datensicherheit und Datenschutz genannt. Auch für Big Data gilt: Die Unternehmen sind unsicher, welche Optionen sie nutzen können und wo sie ggf. in der Nutzung und Auswertung von kundenspezifischen oder arbeitsprozessbezogenen Daten in rechtliche Grauzonen geraten. Dies gilt es näher aufzuschlüsseln, damit das Recht beachtet oder auch an neue Bedürfnisse angepasst werden kann. Zum anderen soll das Recht, etwa in Form von Gesetzesänderungen und Neuregelungen, ein neues Schutzsystem hervorbringen, das den disruptiven Prozessen, die mit Big Data in Verbindung gebracht werden oder aus Big-Data-Anwendungen hervorgehen, Konturen verleihen und Schranken setzen kann. Die Gewährleistung von Rechtssicherheit, die Schaffung von Big-Data-Recht, wird so zu einem „Passepartout“ der Big-Data-Ökonomie.
Solange es noch kein solches ausdifferenziertes Big-Data-Recht gibt – und hierzu bedarf es neben gesetzlichen Spezialregelungen auch einer Kasuistik, die sich in der Rechtsprechung erst über mehrere Jahre entwickeln kann – wird es auch keine hundertprozentig eindeutige und in allen Details vorhersehbare Rechtsanwendung geben.
Eine solche zu fordern, hieße, Innovationen im Keim zu ersticken. Schon deshalb wird man lediglich die Beachtung der zwingenden Rechtsvorschriften verlangen dürfen, um mit der Entwicklung von Big-Data-Instrumenten und der Durchführung von Big-Data-Verfahren zu beginnen. Die Fernwirkungen und Details in den möglicherweise sehr komplexen Rechtsbeziehungen sind quasi „en passant“ zu beobachten und situationsabhängig nachzusteuern. Im Übrigen lassen sich Konflikte auch durch vertragliche Gestaltung vermeiden.
Es sind immer wieder zwei zentrale Interessenabwägungen, anhand derer Big-Data- Prozesse zu gestalten sind : Auf der einen Seite geht es um ein Abwehrrecht der Betroffenen, was im Wesentlichen durch das Datenschutzrecht normativ erfasst wird. Auf der anderen Seite stehen die Verwertungsrechte der Beteiligten im Rahmen der Wertschöpfung von Big Data.
Um die heterogenen Fallgestaltungen eines Big-Data-Workflows zu erfassen, bietet es sich an, diesen in drei grundlegende Phasen zu unterteilen, um diese später nach Bedarf weiter auszudifferenzieren. So ergeben sich die drei Phasen Datenentstehung und Datenerfassung, Datenspeicherung und Datenverarbeitung sowie Datenveredelung und Datenverwertung.
Zwischen solchen Phasen zu unterscheiden, bietet sich auch deshalb an, weil sich die rechtlichen Herausforderungen je nach Phase unterschiedlich darstellen.
3-Phasen-Modell
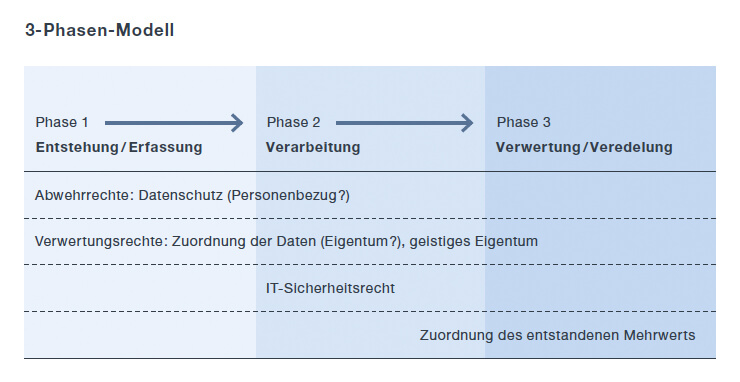
Phase 1 – Datenentstehung und Datenerfassung
Die Phase der Datenentstehung und Datenerfassung stellt zumeist den Beginn der Wertschöpfungskette dar. In rechtlicher Hinsicht liegt hier die wesentliche Weichenstellung im Datenschutzrecht. Es ergibt sich derzeit weitgehend aus dem Bundesdatenschutzgesetz (BDSG), dem Telemediengesetz und Spezialregelungen zu einzelnen Sachbereichen wie etwa den Gesundheitsdaten nach dem Sozialgesetzbuch. Ab 2018 gilt dann europaweit einheitlich die Datenschutzgrundverordnung.
Datenschutzrecht kommt immer dann zur Anwendung, wenn es sich bei den erfassten Daten um personenbezogene Daten handelt. Soweit es „nur“ um sachbezogene Daten ohne Personenbezug geht (z. B. Wetterdaten, reine Fahrzeugdaten, Produktdaten, Daten aus maschineller Steuerung etc.), greift ggf. ein Know-how-Schutz, der Schutz von Betriebs- und Geschäftsgeheimnissen oder mittelbar auch ein Eigentumsschutz, wenn zur Erfassung der Daten physische Hürden zu überwinden sind.
Die Erhebung, Speicherung und Nutzung personenbezogener Daten, wie sie auch in den verschiedenen Phasen einer Big-Data-Anwendung in Betracht kommen, sind datenschutzrechtlich gerechtfertigt, wenn hierfür ein spezieller Rechtfertigungsgrund besteht (z. B. ein zugrunde liegender Vertrag, in dessen Erfüllung die Datenerhebung erfolgt) oder wenn der Betroffene wirksam eingewilligt hat. Beides ist im Kontext von Big Data möglich, aber nicht immer einfach umsetzbar. Sowohl bei der massenhaften Erhebung als auch bei der automatisierten Verarbeitung personenbezogener Daten sind limitierende Vorgaben (Datensparsamkeit, Scoring nach § 28 b BDSG) zu beachten. Für besonders sensible Daten (z. B. Angaben zu Gesundheit oder ethnischer Herkunft, vgl. § 3 Abs. 9 BDSG) gelten weitere Restriktionen. Der Erstellung totaler Persönlichkeitsbilder (Profiling) hat das Bundesverfassungsgericht schon vor mehr als vier Jahrzehnten einen Riegel vorgeschoben. Aus diesen Gründen wird in vielen Big-Data-Szenarien über eine Anonymisierung bzw. Pseudonymisierung versucht, den Personenbezug zu lösen, um nicht mehr den strengen Datenschutzanforderungen unterworfen zu sein.
Schon hier ist die Frage aufzuwerfen, inwieweit die Akteure, ohne die die Datenbestände erst gar nicht erzeugt würden, an einem späteren Gewinn aus der Verarbeitung und Veredelung jener Daten zu beteiligen sind. Das betrifft etwa den Hersteller von Sensoren oder einer Blackbox im Fahrzeug, den Betreiber einer Suchmaschine, aber auch und besonders einzelne Personen, deren (persönliche) Daten erfasst werden. Hier wird erstmals die Frage nach einem „Dateneigentum“ oder nach vergleichbaren Ausschließlichkeitsrechten aufgeworfen. Dies wird am Ende eine Frage der konkreten Vertragsgestaltung sein. Daneben ist bereits an die Verwertungsrechte aus dem Urheberrecht zu denken, soweit die Daten Werkscharakter haben, also Gegenstand eines urheberrechtlichen Schutzes sein können.
Phase 2 – Datenspeicherung und Datenverarbeitung
In der zweiten Phase des Big-Data-Workflows – Datenspeicherung und Datenverarbeitung – geht es um Speichermedien und Verarbeitungsmodi und die damit verbundenen Fragen. Das Datenschutzrecht ist hier weiter relevant, allerdings in Abhängigkeit von der Weichenstellung in der ersten Phase. Soweit der Personenbezug nämlich nicht gelöst wurde (was bei bestimmten Anwendungen auch sinnvoll ist, um etwa bestimmte personalisierte Dienste wie ein Therapieangebot nach Big- Data-Analyse von Gesundheitsdaten erbringen zu können), kommt es in der zweiten Phase besonders darauf an, dass sich die Datenverarbeitung im Rahmen der Rechtfertigung verhält. Nach dem Grundsatz der Zweckbindung muss eine Zweckänderung (so lukrativ diese auch sein mag) vermieden werden, solange man nicht erneut eine entsprechende Einwilligung des Betroffenen einholt, was sehr aufwendig sein kann.
Neben das Datenschutzrecht tritt in der zweiten Phase das IT-Sicherheitsrecht. Gerade die Masse und Komplexität der Daten, die hier gespeichert und verarbeitet werden, erfordern Vorkehrungen zum Schutz der Verfügbarkeit und Integrität, ggf. auch der Vertraulichkeit der Datenbestände. Das IT-Sicherheitsgesetz ist zu beachten, wenn sogenannte kritische Infrastrukturen betroffen sind, also Infrastrukturen in bestimmten Sektoren (z. B. Energie, IKT oder Wasser, vgl. die Verordnung zur Bestimmung kritischer Infrastrukturen – BSI-KritisV – zu der Frage, welche Anlagen darunterfallen), deren Ausfall bzw. Beeinträchtigung zu Versorgungsengpässen und weiteren schädlichen Auswirkungen für Staat und Gesellschaft führen können.
Auch das Urheberrecht erlangt eine besondere Bedeutung in der zweiten Phase, weil und soweit es dort um den Schutz von Datenbanken und die Rechte der hieran Beteiligten geht.
Phase 3 – Datenveredelung oder Datenverwertung
Die dritte Phase eines Big-Data-Workflows kann als Datenveredelung oder Datenverwertung bezeichnet werden. Es geht um besondere Verwertungsmöglichkeiten der aggregierten Daten in unterschiedlichen Kontexten, die mehr oder weniger nahe an den ursprünglichen Datenerfassungsszenarien liegen. Von Datenveredelung kann und sollte auch deshalb gesprochen werden, weil es bei Big Data besonders um Wertschöpfung, also die Schaffung von Mehrwerten geht, die über die einfache Datennutzung bei der klassischen Datenverarbeitung weit hinausgeht. Diesen Mehrwert gilt es – insbesondere über vertragliche Gestaltungen – den am Prozess Beteiligten zuzuordnen.
Komplexität reduzieren – Szenarien bilden
Big-Data-Anwendungen können außerordentlich komplex sein. Unter rechtlichen Gesichtspunkten lohnt es sich, exemplarisch Szenarien („Use Cases“) zu erproben, bei denen die Zahl der unbekannten Faktoren noch überschaubar bleibt.
Die Bandbreite der Anwendungsmöglichkeiten für die Wertschöpfung durch Verarbeitung großer Datenmengen ist enorm. Von der Energiewende über neue Verkehrssysteme, medizinische Forschung und Diagnostik, der Vorhersage von Krisensituationen, der Lagebewertung und Gefahrenabwehr zur Verbesserung der inneren Sicherheit, neuen Finanzdienstleistungen bis hin zu Connected Car, digitalen Einkaufswelten, adressatengenauem Online-Marketing und Industrie 4.0 : All das, was man mit Big Data verbinden kann, ist letztlich nichts anderes als die konsequente, den derzeitigen und künftigen technologischen Möglichkeiten der Datenerfassung, Datenverwertung und Datenveredelung folgende Zusammenführung von Nutzerinteressen und Geschäftsmodellen. Bei allen Unklarheiten und Unwägbarkeiten sind doch ein hoher gesellschaftlicher Nutzen und erhebliche Gewinne durch Big-Data-Anwendungen zu erwarten.
In einer Big-Data-Matrix kann man ermitteln, ob ein Anwendungsfall unter rechtlichen Aspekten eher trivial oder besonders anspruchsvoll ist. Rechtliche Relevanz haben besonders Kriterien wie die konkrete Einwilligung der Betroffenen, die Anforderungen an Anonymisierung oder Pseudonymisierung, die Art und Menge der Daten oder die Zweckbindung.
Offene Rechtsfragen
Eine Vielzahl von Rechtsfragen im Zusammenhang mit dem Einsatz von Big-Data-Methoden ist heute aber schlicht noch nicht abschließend geklärt. Im Folgenden nur einige Beispiele :
Einwilligung
Nach geltendem Datenschutzrecht gilt der Grundsatz der informierten Einwilligung (§§ 4, 4 a BDSG). Der Betroffene muss demzufolge die Tragweite seiner Entscheidung vorhersehen können, also genau wissen, was mit seinen personenbezogenen Daten geschehen soll. Das ist bei Big-Data-Anwendungen eine große Herausforderung, weil und soweit die Verarbeitung und Verwertung der Daten weit über den ursprünglichen Zweck hinausgehen können. Teilweise wissen die Anbieter von Big-Data-Analysen im Zeitpunkt des Datenzugriffs selbst noch nicht abschließend, wofür die Daten einmal verwendet werden sollen. Und selbst wenn dies in einem Fall bekannt sein mag, sind doch Folgeverwendungen, die Übermittlung an Dritte und spätere Zweckänderungen denkbar, über die zunächst nicht informiert wird (oder werden kann).
(Kein) Dateneigentum
Bei Big-Data-Verfahren stellt sich nicht nur die Frage, mit welchen Schutzrechten und Schutzpositionen sich der Einzelne gegen die Erfassung „seiner“ Daten wehren kann. Vielmehr ist auch zu klären, wie er – umgekehrt – an der Verwertung / Vermarktung dieser Daten partizipieren kann. Das betrifft zum einen den Nutzer / Verbraucher, um „dessen“ Daten es geht. Daneben treten weitere Berechtigte auf den Plan. Aus diesem Grund sind vor der Konzeption von Big-Data-Anwendungen die Schutzrechte der einzelnen Akteure zu klären, um die Anwendung nicht nur zum Laufen zu bringen, sondern auch das Geschäftsmodell durchzurechnen.
Nach geltendem Recht gibt es Eigentum aber nur an körperlichen Gegenständen, also kein Dateneigentum. Rohdaten als Bestandteile der Datenmengen in Big-Data-Verfahren sind überdies weder immaterialgüterrechtlich geschützt noch schutzfähig. Vom Urheberrecht abgesehen, entstehen die weiteren Immaterialgüterrechte immer erst nach einem gesetzlich genau vorgeschriebenen Publizitätsakt (Veröffentlichung im Patentblatt, Eintragung ins Markenregister usw.). Die Entstehung und Erfassung eines Datums, die nachfolgende Speicherung und auch das spätere Veredeln sind davon nicht erfasst.
Urheberrecht
Der urheberrechtliche Werkschutz verlangt eine persönliche geistige Schöpfung, vgl. § 2 Abs. 2 UrhG. Das einzelne Datum ist häufig eine rein maschinelle Produktion, besitzt für sich allein genommen keinen geistigen Gehalt und nicht die erforderliche Schöpfungshöhe. Daher kommt dem einzelnen Datum auch kein urheberrechtlicher Werkschutz zu. Abgesehen davon mögen Big-Data-Anwendungen auch weitere Daten hervorbringen, die alleine durch technische Analysen entstehen, sodass kaum von einer persönlichen Schöpfung gesprochen werden kann, für die Urheberschutz beansprucht werden könnte. Zwar darf sich ein Urheber technischer Mittel bedienen. Der Mensch darf die Maschine aber nicht lediglich beherrschen, sondern muss mit ihrer Hilfe aus eigener geistiger Quelle eine schöpferische Gestaltung hervorbringen. Solange das kreative Programm wirklich in einer Maschine „verkörpert“ ist, folgen faktisch das Recht an den Ergebnissen bzw. die Verfügungsmöglichkeit über die Ergebnisse dem Eigentum an der Maschine. Als (Leistungs-)Schutzrechte kommen bei Big Data deshalb eher solche aus § 87 b UrhG für die Betreiber der Datenbanken in Betracht.
Patentrecht
Demgegenüber scheidet ein patentrechtlicher Schutz weitgehend aus. Hierfür müsste eine Big-Data-Datenanalyse eine „technische Außenwirkung haben“. Das heißt, dass die Software die Lösung eines technischen Problems mit technischen Mitteln bestimmen oder zumindest beeinflussen muss, wie es wohl oftmals im Rahmen der industriellen Produktion der Fall sein wird. Daran kann es fehlen, wenn es im Rahmen von Big-Data-Datenanalysen nicht um die Lösung eines technischen Problems mit technischen Mitteln, sondern eher um die Lösung eines tatsächlichen Problems mit technischen Mitteln geht.
IT-Sicherheit
Selbst wenn eine grundsätzliche Erlaubnis besteht, Massendaten zu erfassen, ist dies kein Freibrief für die weitere Behandlung. So müssen die Daten sicher verwahrt und verarbeitet (evtl. auch anonymisiert) werden. Hierzu zählen insbesondere die Gewährleistung der Verfügbarkeit, Integrität und Vertraulichkeit der Daten. Sowohl die Rohdaten als auch die aggregierten Daten müssen so gespeichert und zum Abruf bzw. zur weiteren Verwendung vorgehalten werden, dass der Berechtigte jederzeit Zugang hat, der Unbefugte wiederum wirksam ausgeschlossen bleibt. Außerdem ist ein Schutz vor Manipulation der Datenbestände (von innen und von außen) zu bewerkstelligen, weil sonst die Datenbasis verfälscht und die Schlussfolgerungen aus der Analyse fehlerhaft wären. Das Sicherheitsniveau muss der Bedeutung der jeweiligen Big-Data-Anwendung angepasst werden. Allerdings sind unter anderem die Haftungsmaßstäbe noch weitgehend ungeklärt.
Insgesamt ist die Gewährleistung der IT-Sicherheit gerade bei Big-Data-Anwendungen wichtig und anspruchsvoll zugleich. Big Data ohne IT-Sicherheit ist wertlos und kann sogar gefährlich sein. Wenn ganze Big-Data-Workflows und Wertschöpfungsketten von der Verfügbarkeit und Integrität der durch sie erhobenen Daten abhängen, stellt eine Kompromittierung jener IT-Sicherheit das gesamte System infrage.
So sehr man sich um eine rechtskonforme Gestaltung von Big-Data-Anwendungen und die Gewährleistung von IT-Sicherheit bemühen kann und bemühen sollte, so klar ist zugleich, dass man IT-Unsicherheit bzw. IT-Risiken mit den daraus erwachsenden Schäden nicht vermeiden kann. Parallel zum IT-Sicherheitsrecht muss ein Informationshaftungsrecht und Informationsfolgenrecht entwickelt werden, dessen Konturen bislang nur leicht ausgeprägt wurden.
Gesetzlichen Rahmen schaffen
In der Tat ist das geltende Recht nicht in der Lage, alle Fallgestaltungen im Kontext von Big-Data-Anwendungen zufriedenstellend abzudecken. Die Akteure sind daher gefordert, den Interessenausgleich einschließlich der Nutzungs- und Verwertungsrechte sowie der Erlösanteile rechtsgestaltend durch Verträge selbst in die Hand zu nehmen. Die besondere Herausforderung aus rechtlicher Sicht ist, jenen gesetzlichen Rahmen zu schaffen, der Orientierungssicherheit für alle Akteure gibt, ohne deren innovative Entfaltung zu behindern. Für den Gesetzgeber bedeutet dies zugleich, das richtige Maß an Regulierung zu finden. Detailverliebtheit wäre hier genauso kontraproduktiv wie die Scheu, Weichen zu stellen und damit die Übernahme von Verantwortung für die Folgen technischer Innovationen zu verweigern. Dies führt auch zu der notwendigen Diskussion um die Bedeutung normativer Steuerung der Technikentwicklung.